How it works
Amplify DataStore provides a persistent on-device storage repository for you to write, read, and observe changes to data if you are online or offline, and seamlessly sync to the cloud as well as across devices. Data modeling for your application is using GraphQL and converted to Models that are used in JavaScript, iOS, or Android applications. You can use DataStore for your offline use cases in a “local only” mode without an AWS account or provision an entire backend using AWS AppSync and Amazon DynamoDB. DataStore includes Delta Sync using your GraphQL backend and several conflict resolution strategies.
How it Works
Amplify DataStore is an on device persistent repository for interacting with your local data while it synchronizes with the cloud. The core idea is to focus on your data modeling in your application with GraphQL, adding any authorization rules or business logic into your application when needed. This can be done using Amplify CLI project functionality (amplify add auth or amplify add function) as well as the GraphQL Transformer.
Model data locally
Starting with GraphQL schema (with or without an AWS account) a code generation process creates Models which are domain native constructs for a programming platform (TypeScript, Java, Swift classes). This "modelgen" process happens using the Amplify CLI which is either done manually in your terminal or using build tools that will invoke the CLI process (NPX scripts, Gradle, Xcode build phase).
Once Models have been generated, you can operate on these instances with the DataStore API to save, query, update, delete, or observe changes. At runtime models are passed into a Storage Engine that has a Storage Adapter. The Storage Engine manages a "Model Repository" of Models which were defined by the developer's GraphQL schema as well as "System Models" which are used for both metadata (such as settings) and queueing updates over the network when syncing to the cloud. Amplify ships with default Storage Adapter implementations, such as SQLite and IndexedDB, however the pattern allows for more in the future for community contributions and is not specific to one technology (e.g. SQL vs NoSQL).
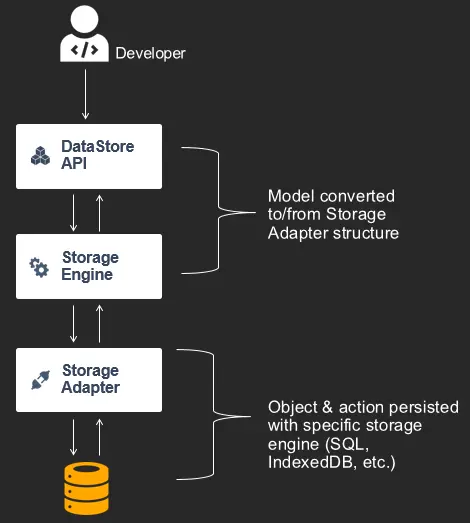
When developer application code interacts with the DataStore API, it is the responsibility of the Storage Engine to store the specific Model for a GraphQL type in the Model Repository as well as serialize & deserialize as appropriate for persistence in the specific Storage Adapter representation. This includes conversion from a GraphQL specific type the appropriate structure in that database engine (e.g. Int to Int64).
Sync data to cloud
If a developer chooses to sync with the cloud, the Amplify CLI will use the GraphQL schema to deploy an AWS AppSync backend with DynamoDB tables for each type and an additional table used for Delta Sync. Other AWS services such as Amazon Cognito or AWS Lambda will also be deployed if added to the project. Once this completes the local configuration for the platform (aws-exports.js or amplifyconfiguration.json) will be generated inside the project and updated with settings and endpoint information.
An application should never write to or modify the Delta Sync table. It is internal to the DataStore implementation.
If the DataStore starts up and sees API information to sync with an AppSync endpoint, it will start an instance of its Sync Engine. This component interfaces with the Storage Engine to get updates from the Model Repository. These components use an Observer pattern where the Sync Engine publishes events whenever updates happen in it (such as data being added, updated, or deleted) and both the DataStore API and Sync Engine subscribe to this publication stream. This is how the developer knows when updates have happened from the cloud by interacting with the DataStore API, and conversely how the Sync Engine knows when to communicate with the cloud when applications have made updates to data.
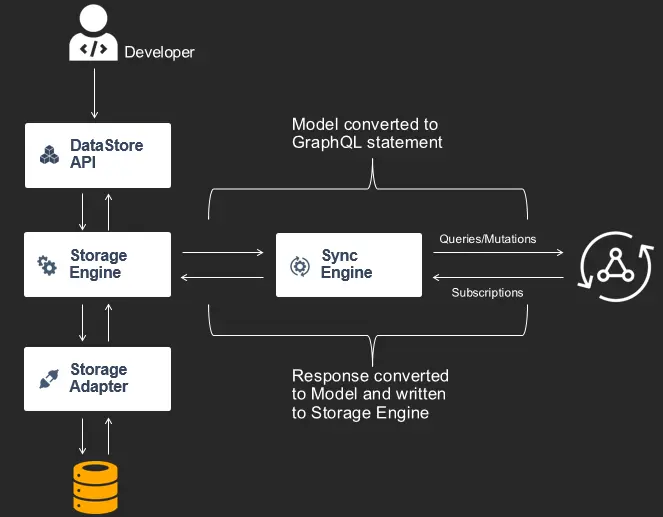
As notifications come into the Sync Engine from the Storage Engine it converts information from the Model Repository into GraphQL statements at runtime. This includes subscribing to all create/update/delete operations for each type, as well as running queries or mutations.
The Sync Engine will run a GraphQL query on first start that hydrates the Storage Engine from the network using a Base Query. This defaults to a limit of 100 items at a time and will paginate through up to 1000 items. It will then store a Last Sync Time and each time the device goes from an offline to online state, it will use this as an argument in a Delta Query. When AppSync receives this Last Sync Time in its argument list, it will only return the changes that have been missed by pulling items in a Delta Table.
All items (or "objects") are versioned by Sync Enabled Resolvers in AppSync using monotonically increasing counters. Clients never update versions, only the service controls versions. The Sync Engine receives new items or updates from GraphQL operations and applies them with their versions to the Storage Engine. When items are updated by application code they are always written to a queue and the Sync Engine sends them to AppSync using the currently known version as an argument (_version) in the mutation.
Conflict resolution
When multiple clients send concurrent updates using the same version and conflict resolution is configured, a strategy for conflict resolution will be entered. The default strategy for clients is Automerge where the GraphQL type information is used to inspect the update and compare it to the current item that has been written to your table. Any non-conflicting fields are merged with the item and any lists will have values appended, with the service updating the item version as appropriate. You can change this default to apply version checks to the entire object with Optimistic Concurrency where the latest written item to your database will be used with a version check against the incoming record, or alternatively you can use a Lambda function and apply any custom business logic you wish to the process when merging or rejecting updates. In all cases the service controls the versions. For more information on how these conflict resolution rules work please see the AWS AppSync documentation.
Writing data from the AppSync console
DataStore is designed primarily for developers to not have to focus on the backend and let your application code and workflow create everything. However, there will be some use cases where you will use the AppSync console, a Lambda function, or other out of band processes to write data (such as batch actions or data migrations) and you might send GraphQL operations without the DataStore client.
In these cases it's important that the selection set of your GraphQL mutation includes all the required fields of the model, including: _lastChangedAt, _version, and _deleted so that the DataStore clients can react to these updates. You will also need to send the current object version in the mutation input argument as _version so that the service can act accordingly. If you do not send this information the clients will still eventually catch up during the global sync process, but you will not see realtime updates to the client DataStore repositories. An example mutation:
mutation UpdatePost { updatePost( input: { id: "12345" title: "updated title 19:40" status: ACTIVE rating: 5 _version: 7 } ) { id title status rating createdAt updatedAt _lastChangedAt _version _deleted }}